The work discussed in this blog was presented to the COVID-19 Mobility Data Network on September 25, 2020, as part of regular weekly meetings that aim to share information, analytic tools, and best practices across the network of researchers.
The COVID-19 pandemic has underscored the importance of developing analytical pipelines that leverage data streams generated by individuals and communities to drive data-driven responses to crises. As these data increasingly exchange hands within agencies and are shared publicly for broader research, Salil Vadhan from Harvard SEAS and Navin Vembar from Camber Systems discuss the inadequacy of traditional methods for the protection of sensitive personal data.
Conventional methods of removing “personally identifiable information” or aggregating data above the individual level are antiquated, inadequate, and vulnerable to attacks. There are now numerous examples that demonstrate that the removal of PII still leaves data vulnerable to re-identification of individuals through the use of auxiliary datasets, shown through examples in medical data, and even through the Netflix database. Even with aggregate statistics, it is now possible to reconstruct almost the entire underlying dataset, demonstrated using publicly available Census data, or even to determine whether a target individual is in a dataset, for example using genomic data.
As the sophistication of these attacks on privacy grew, Differential Privacy (DP) evolved as a means of ensuring that individual-level information cannot leak when releasing statistical information. The goals of differential privacy, as detailed by the presenters, are to enable the collection, analysis, and sharing of a broad range of statistical estimates based on personal data, such as averages, contingency tables, and synthetic data, while protecting the privacy of the individuals in the data. This is achieved by injecting small amounts of random noise into statistical computations to hide the effect of each individual subject while still allowing useful inference and statistical analysis of the population data. There is a growing base of mathematical literature showing that, in principle, DP is compatible with almost all forms of statistical analysis of populations.
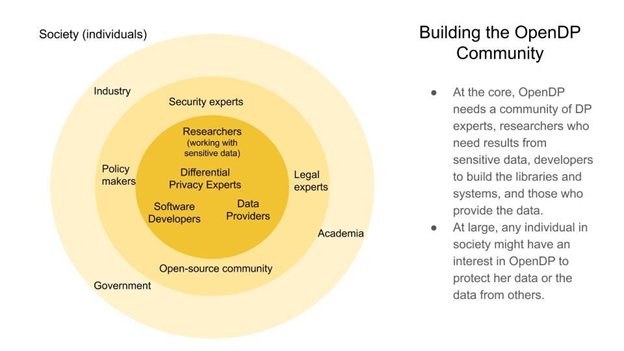
The OpenDP Project is a community effort led by the School of Engineering & Applied Sciences (SEAS) and the Institute of Quantitative Social Sciences (IQSS) at Harvard University to build a trustworthy and open-source suite of DP tools that can be easily adopted by custodians of sensitive data to make it available for research and exploration in the public interest. The goal of OpenDP is to open otherwise siloed and sequestered sensitive data to support scientifically oriented research and exploration in the public interest, including data shared from companies, government agencies, and research data repositories.

OpenDP software aims to provide statistical functionality that is useful for the researchers who will analyze data while exposing measures of utility and uncertainty that will help researchers avoid drawing incorrect conclusions due to the noise introduced for privacy. It was developed to channel the collective advances in the DP community on science and practice, enable wider adoption to address compelling use cases, and identify important research directions for the field. Some of the high-priority use cases identified by OpenDP include:
- Archival data repositories to offer academic researchers privacy-preserving access to sensitive data.
- Government agencies to safely share sensitive data with researchers, data-driven policymakers, and the broader public.
- Companies to share data on their users and customers with academic researchers or with
institutions that bring together several such datasets. - Collaborations between government, industry, and academia to provide greater access to and
analysis of data that aids in understanding and combating the spread of disease.
The future collaboration between IQSS and CrisisReady will address the challenges of enforcing privacy-protective analysis at scale, by embedding differential privacy by design into developed data pipelines.
As the OpenDP community continues to grow, you can stay involved with the team’s work by looking through their whitepapers, videos, and software at http://opendp.io/, exploring their Github, subscribing to their blog, joining the community mailing list, or get in touch at info@opendp.io.