Ensuring Privacy in Disease Spread Research Using Differential Privacy Techniques
Members and collaborators of the CrisisReady team have published research that presents a new way to keep people’s personal information safe when studying how diseases spread using mobile phone data. This method, called differential privacy, works by adding statistical noise to data to protect the privacy of individuals while preserving the utility of the data for analysis. This helps to hide individuals’ personal information but still allows researchers to understand important patterns in the disease spread.
The team looked at how adding privacy protection affects ten different measurements used in tracking how COVID-19 spreads and how effective control measures are. They discovered that these measurements remained accurate even when they added quite a bit of random data to protect privacy. The research suggests using a privacy setting of ϵ = 0.05 each time they share data, which is a way to ensure people’s information is kept private.
The research team provided a modular software pipeline to facilitate the replication and expansion of their framework. This pipeline includes four modules:
- Data preprocessing
- Differential privacy
- Epidemiological modeling
- Evaluation
Each module is designed to be independent and interchangeable, allowing researchers to use their own preferred methods for each module. The authors also provided a step-by-step guide for implementing their framework, which includes code snippets and example data.
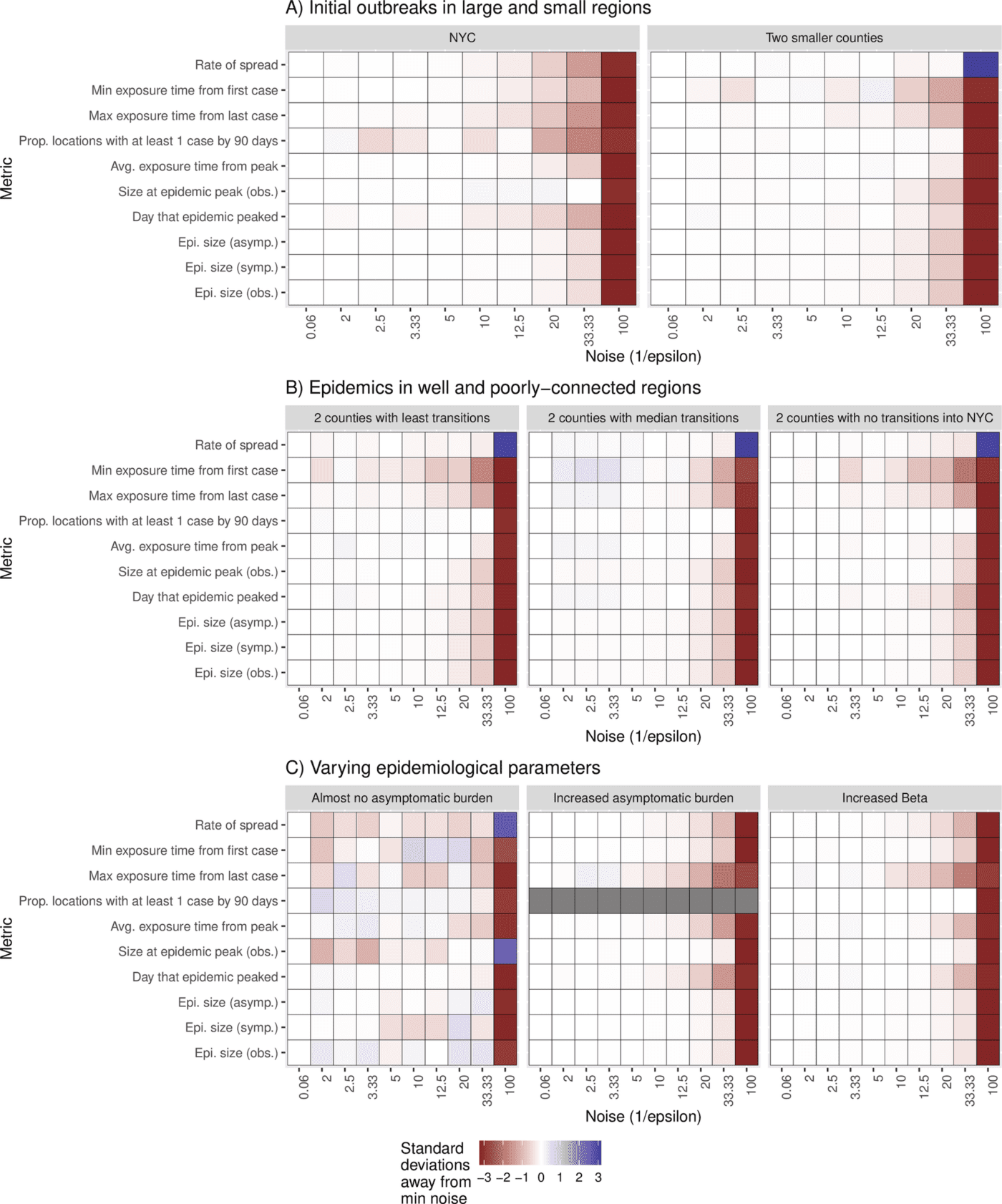
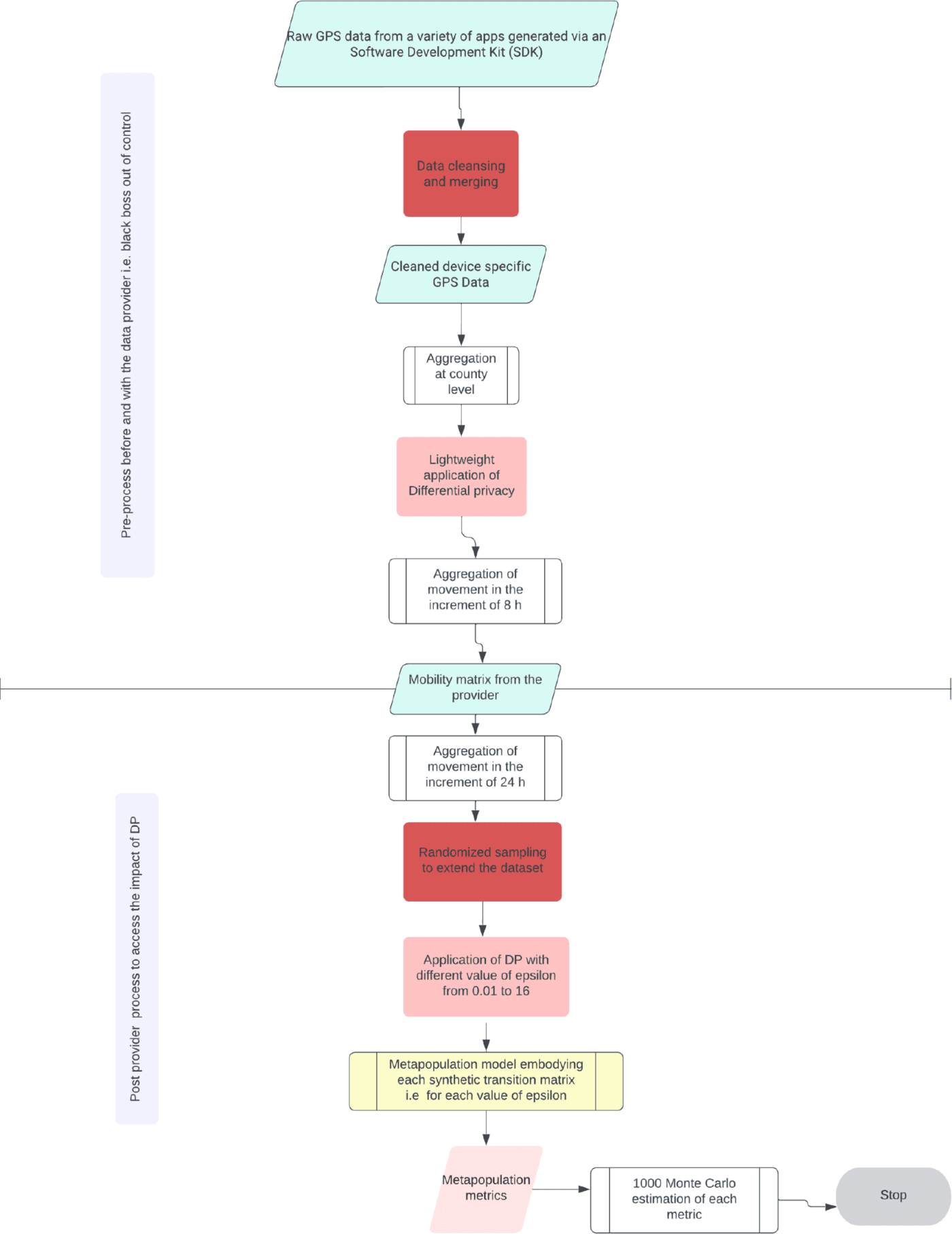
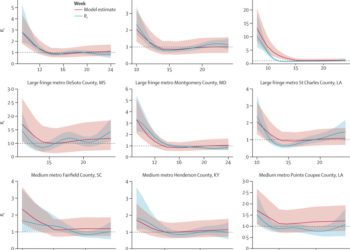
Fig 1. (right) Metapopulation metric distribution for different values of epsilon for Scenario A, B, and C.
- Scenario A: Location of the first cases
- Scenario B: Change in the mobility network.
- Scenario C: Change in the parameters of the metapopulation model.
As metrics can exist on very different scales, we calculate the normalized distribution of bootstrapped metrics where a minimum amount of noise is added. We then compare this to the median value of bootstrapped values at increasing values of noise to describe the change from expectation.
Fig 2. (left) Flow diagram showing the architecture of the modular software pipeline designed to quantify the tradeoff privacy utility of mobility data post-differential privacy processing in epidemiological models.
In this figure, the boxes in pink represent the DP process, the boxes in red represent cleansing processes by both data providers and modelers, the boxes in green represent the data, the boxes in white are predefined processes, and the box in yellow stands for the metapopulation model.
The research introduces a consistent method for using differential privacy with mobile phone data when studying disease patterns. This method is designed to be adaptable, meaning researchers can tweak it to fit their specific projects. The results of the research show that this method works well for keeping personal information secure while still making sure the data is useful for analysis.
This research works hand in hand with the OpenDP project. The project, led by members of the CrisisReady team and experts at Harvard’s School of Engineering & Applied Sciences (SEAS) and the Institute of Quantitative Social Sciences (IQSS), aims to develop a set of free tools that anyone can use to safely share sensitive data. The idea is to help researchers gain access to important data that’s usually kept private because it could reveal personal information. With these tools, researchers can study the data without risking people’s privacy.
Research Team
- Satchit Balsari
- Caroline O. Buckee
- Nishant Kishore
- Koissi Savi Merveille
- Andrew Schroeder
- Salil Vadhan
- Navin Vembar
- Akash Yadav
- Wanrong Zhang
Team members listed alphabetically by last name.